
Current Webinar Register Now
You’re invited to join the webinar.
Capturefast team will show you the easiest OCR and capture service.
Please join us to learn more.
Tuesday, 21 June 02:00 PM America/New_York
Upcoming Webinars
Tuesday, 21 June 02:00 PM America/New_York
* Please do not hesitate to ask for a private session if the webinar time does not suit youContact Us
left!
OCR [/ˌoʊ.siːˈɑːr/]
OCR
Verb[ T ],
To convert an image into text:
I OCRed my homework and published it on a blog post by using Capturefast.
Noun [ U ], OCRing
The process of converting an image to text:
I heard Capturefast is the best OCRing software.

OCR is the electronic conversion of images of typed, handwritten, or printed text into machine-encoded text, whether from a scanned document, a photo of a document.
Widely used as a form of data entry from printed paper data records – whether passport documents, invoices, bank statements, insurance documents, ACORD forms, e-mails, printouts of static-data, or any suitable documentation – it is a common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as cognitive computing, RPA processes, machine translation, (extracted) text-to-speech, key data, and text mining. OCR is a field of research in pattern recognition, artificial intelligence, and computer vision.
Why do you need OCR?
OCR is used across industries and departments for a variety of business processes due to its flexibility and efficiency as a scanning tool. In the context of digital content management, OCR has two primary functionalities that are applicable to any business: eliminating data entry and capturing information. The newly captured information can then be searched for and even be used to initiate or fill in data as part of a business process workflow.
Are all OCR engines the same?
Quick answer, no! Each OCR engine has some pros and cons. While some of them are good at speed some of them are better at accuracy. Tesseract OCR is the only freeware OCR engine you can simply add to your project. But Tesseract OCR is so bad at segmentation, that’s why most of the serious commercial applications don’t use it. It can be used for very simple and clean images. Tesseract can miss very important data if the document is a little bit complex such as invoices or insurance documents.

1st generation OCR engines
The 1st gen engines needed to be trained with images of each character and worked on one font at a time. Abbyy FineReader and Nuance Omnipage (Now Kofax) are the most famous first generation OCR engines. The first generation OCR engines take the character from the image and compares it optically one by one to the images in their character database. The engine produces a confidence level for each letter of each font. And, picks the highest one up. The 1st gen OCR engines are brute force systems. Even though they’re still the best at machine-printed applications, 2nd gen OCR engines will replace them soon.
2nd generation OCR engines
The 2nd gen OCR engines (some say OCR 2.0) are developed by using ML (Machine Learning) and DL (Deep Learning) algorithms. The ML/DL models are trained by millions of labeled data. Since they don’t use a comparison library, they don’t need to be trained for certain fonts. They can recognize hand-written text or even a human alphabet which is impossible for a 1st gen OCR engine. All of the 2nd gen OCR engines are running on cloud such as Google Vision API, Microsoft Azure OCR, and Amazon Textract.
How to OCR a PDF file?
The third one is “Searchable PDF”. Actually, it shouldn’t be named as another type because both digital PDFs or scanned files could be searchable. As mentioned before, digitally created PDF files are naturally searchable PDF files since they have a text layer. The scanned PDF files can also be a searchable PDF file if an OCR engine creates a text layer over the image. The document scanner drivers always use unsuccessful, speed-optimized cheap OCR engines to create text layers. That’s why the text layer of a scanned PDF must be ignored. Capturefast, the best OCR engine in the world, never uses the text layer to extract information from scanned-searchable-PDF files. Instead, It re-OCRes the image layer of the PDF file. A good OCR engine must be smart enough to recognize the PDF type and use the appropriate technology to scrape the text.
The second type of PDF file is scanned PDF, image PDF, or image-only PDF. MFDs, fax servers, and document scanners create this type of PDFs by scanning physical paper documents. Scanned PDFs are not so different than TIF files or JPEG files. They must be OCRed as a regular image.
PDF is the most used file type in the document processing market since it is also the easiest way of document sharing and managing. A PDF can hold text, tables, and images on multiple pages. There are three types of PDF files. True PDFs, Digitally created PDFs, Digital PDFs, Native PDFs, or Natural PDFs are all the same thing. It keeps the objects (Texts, tables) in vector format. This type of PDF file is naturally a “searchable PDF” since it keeps text as digital data in a separate layer. So a good OCR engine should use the text layers instead of rendering the content into an image and then OCRing it. Rendering the image to OCR decreases the accuracy and slows down the operation.
How can you improve OCR accuracy?
A scanned document image is half digital, half analog. It is digital because it is stored in a digital file on a computer. But the information in it is still analog because nobody knows it is there. An OCR engine can extract the data from it and makes the information reusable for the world. The information is useless for automated systems if the information is not classified and segmented perfectly. To do so, you have to trust the accuracy rates of the OCR engine. As with all the analog to digital transformation processes, you have to accept some error rate.
The average success rate of an OCR engine for regular office documents is over %95. But anything less than 100% OCR accuracy creates massive error rates for the business. You may accept 95% accuracy for full-text search, but not for automated data extraction. Can you imagine, your OCR system is recognizing everything right but the total amount? How can you automate your account payable operations with miss recognized values on each invoice? Automation needs 100% OCR accuracy, but it’s impossible using OCR alone.
Here are some tips to improve OCR accuracy:

Scanning quality: The best way of improving the OCR accuracy is by using a professional document scanner if you have control over scanning settings. There are lots of scanner models from Fujitsu, Canon, Ricoh, and Kodak in the market. The professional document scanners are like professional cameras, they do the best whatever you scan. But we all know that %99 of the images are not created by a professional document scanner.

So, how to improve the OCR accuracy for low-quality images? The MFDs (Multifunctional devices) are generally, but wrongly, being used in 200 DPI mode to speed up the scanning and forwarding of the documents. Fax servers that can send documents in 96 DPI are quite old technologies that are still heavily used. The scanning applications on smartphones also produce either low-resolution or low-quality images. The image quality needs to be improved before an OCR process for all these types of images.
Capturefast’s preprocessing algorithms are the best ones in the world to improve the OCR accuracy rate on those low-resolution/low-quality images. The system deskews the image, removes the horizontal and vertical lines, despeckles the unwanted scanning artifacts, and detects the text blocks for the OCR engines.
Here is a comparison table for well-known OCR engines:
| OCR Tool | Ideal Image | Digital-PDF | Camera Image | Table Extraction | Fax images | Low resolution | OMR |
| CaptureFast | Good | Best | Good | Best | Best | Best | Best |
| Tesseract | Acceptable | None | Poor | None | Poor | Poor | None |
| Abbyy | Good | Poor* | Good | Good | Acceptable | Acceptable | None |
| Good | Poor* | Good | Poor | Good | Good | None | |
| Amazon Textract | Good | Poor* | Good | Good | Poor | Poor | None |
| Microsoft OCR | Good | Poor* | Good | Poor | Acceptable | Acceptable | None |
* The engines other than Capturefast do not use the text layer of the digital PDFs. They render the document into an image and use OCR algorithms. That way decreases the accuracy if the document has lines, shapes and images in it. Capturefast instead, scrapes the text layer to retrieve the words. This way is the best for capturing the data from Digital PDFs.
OCR or Capture?
“OCR” is not equal to “capture”. Then, what does “capture” mean in the document processing industry? Data capture, advanced capture, smart text extraction, intelligent document processing, cognitive extraction are almost the same in the industry. All those adjectives add some fancy and trendy feeling to a software solution. OCR engines extract the words, sentences from the documents without trying to understand the content. Capture systems instead use those words to find the important and required field values to feed decision-making systems such as CRM tools, RPA tools, and DBs.
Zonal OCR
Some legacy systems are still extracting the field values from certain locations of a document. Some software companies name them as structured documents. This method is useful for fixed-layout documents only.
Semi-structured documents
Semi-structured documents are the documents you know what to extract but don’t know where to find them. Incoming invoices are good examples of this type of document. You want to retrieve the invoice number, date, order number, line items, and the total amount. But the invoice layout differs from a vendor to another. The intelligent capture systems such as Capturefast use some methods to find the required information without using a template design.

Non-structure documents
Non-structured documents are similar to semi-structured documents but you have to classify them first. An insurance claim document is a good example of it. Capturefast reads the content and matches the document with one of the semi-structured document types by using a classification module. Capturefast has one of the best auto-classification systems in the market based on its unique hybrid technology.
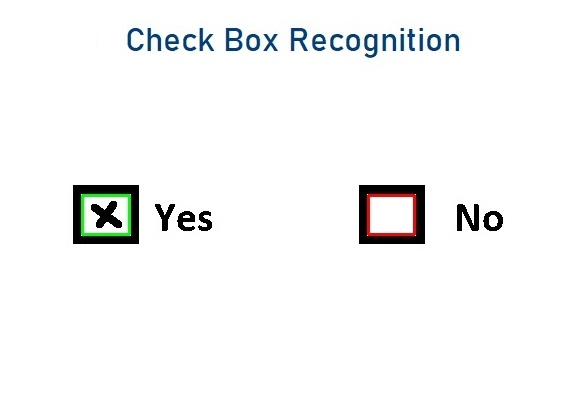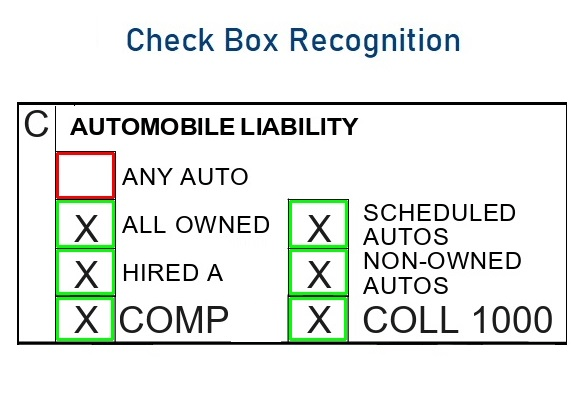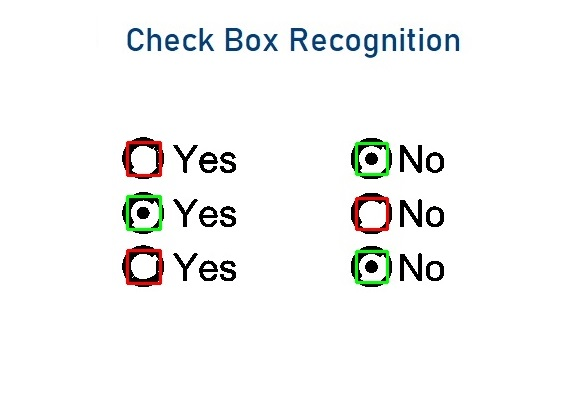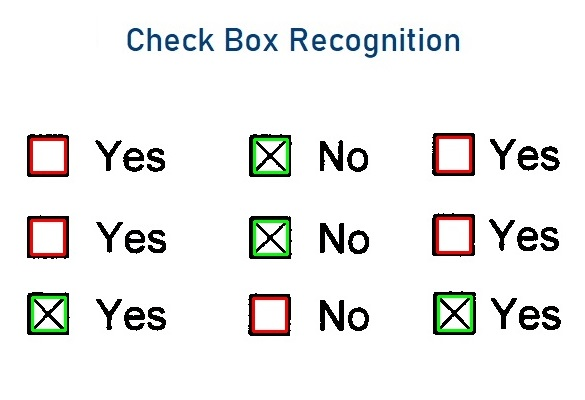
Checkbox detection and OMR (Optical Mark Reading)
Checkboxes are not only the fastest way of giving information but also very useful to classify the information needed.
That must be the reason almost all loan application documents, insurance documents such as ACORD forms are full of checkboxes. Even though a checkbox is not a character to be recognized, capture systems must detect and recognize the data from them.
Capturefast had developed and trained one of the best checkbox detection ML models to reach out to the highest accuracy rates.
Table detection
Extracting data in tables on documents could be challenging for any capture system.
Although some tables have separated cell rectangles or lines between line items, most of the tables are so complex to find perfect rules set to detect and recognize them.
The new ML (Machine Learning) and DL (Deep learning systems) models are now helping Capturefast to detect the table and recognize the table structure without any human help.
It is now not that difficult to extract table content from invoices, bank statements, or complex reports.

Leverage document capture with CaptureFast
Sign up to start. Then create your first document type. Finally, capture data from documents easily.