Auto Document Classification
Auto document classification is one of the main activities for effectively managing text and unstructured information.
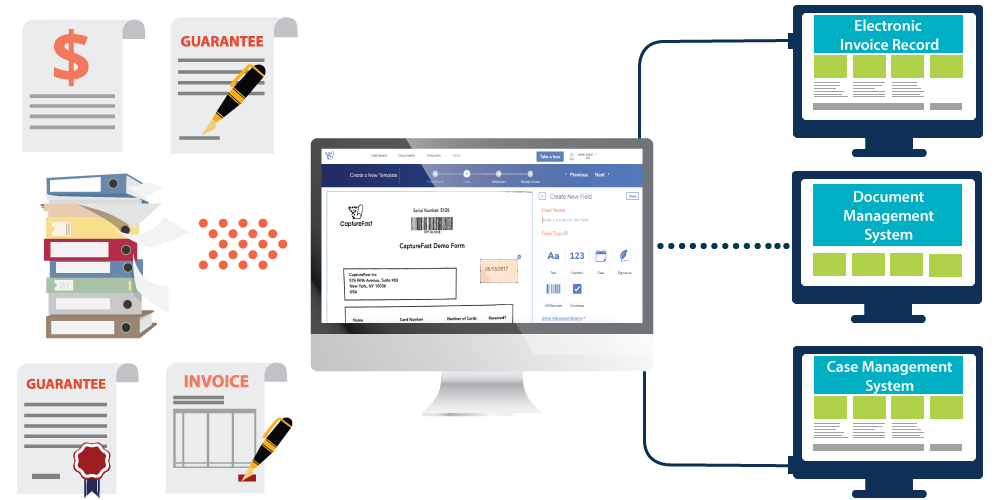
Document classification is the first and the most important step of the document and data capture processes. Prior to extraction, the classification of the document has to be done because different types of documents normally have different extraction fields. Once the classification has been successfully carried out, the document type-specific field extraction can be started.
There are several approaches and methods to pass this step automatically. There is no one “the best” approach for now. AI (Machine learning methods) tools are more popular than rule-based systems for the sales and marketing teams these days.
 While the rule-based systems mostly used for a limited number (less than 1000) of document types such as insurance, banking, operational documents and forms, AI tools is used for unlimited and unstructured documents (not the forms) such as emails or social media shares.
While the rule-based systems mostly used for a limited number (less than 1000) of document types such as insurance, banking, operational documents and forms, AI tools is used for unlimited and unstructured documents (not the forms) such as emails or social media shares.
AI tools must be trained with hundreds of thousands of documents. Machine learning methods needs at least 1000 true and 1000 false pre-classified samples for each type of documents. The neural network is created with the help of these training sets. If the system is trained incorrectly, you have to start from scratch which is almost impossible to find out the miss-classified documents. On the other hand, there are premade neural networks for AI tools to classifies emails and spam blockers. You have to accept some error rate for AI systems.
CaptureFast’s well-known and successful auto-classification system is a rule-based system. Adding a document type into the system is less than 10 minutes. Although it is extremely easy to use, it is quite advanced and accurate. The accuracy target is %100 for CaptureFast Automatic Classification system.
Here are the features CaptureFast Automatic Classification System:
- QR code / Barcode based classification
- Glyph-based classification
- Optical layout-based classification
- Text existence-based classification. Must exist and/or Must not exists.
- The distance between the text blocks-based classification.
- Regular expressions
- Recognition areas such as Upper half of the document, Header, Footer or the entire document.
Capturefast’s new hybrid (AI + Rule) auto-classification system!
The existing rule-based system almost perfect for a capture system. But it still needs some human touch to set it up. On the other hand, when the number of document types increases, more time needed to fine-tune the classification for each document type. CaptureFast engineers decided to add an AI layer for the existing system.
The workflow of the new hybrid system is not changed. But how?
The rule-based classification system uses a DEF table for each document type which must be created by an analyst. Here is a very simple DEF table ingredient of a loan document.
IDPOINT~180
OBJECT~200~0~(0,0,250,250)~image-234
BARCODE~200~0~(0,0,1000,250)~reg exp
ID~200~0~(0,0,1000,330)~”UNIFORM RESIDENTIAL LOAN APPLICATION”~95~reg exp
ID~100~0~(0,0,1000,250)~”AGENCY”~100~ [A,B,C][0-9]{10}
ID~100~0~(0,0,1000,1000)~”LENDER”~100~reg exp
ID~100~0~(0,0,1000,1000)~”PURPOSEOFLOAN”~97~reg exp
ID~100~0~(0,0,1000,1000)~”ORIGINALCOST”~98~ ^-?(?:0|[1-9]\d{0,2}(?:,?\d{3})*)(?:\.\d+)?$
Each line represents a clue to get the document type. The recognition engine uses these DEF tables to classify each document.
The new hybrid system automatically creates the DEF table for the document types by the given samples documents. Hereby, while the successful rule-based system is still being used, the AI portion of the system optimizes the automatically created DEF classifiers for every new document type.
How the new AI works?
The hybrid engine requires at least 100 true and 100 false documents for each document type. The AI extracts the common objects in each document such as images, captions, barcode/QRcodes or labels from the given samples. Another AI tool optimizes each component from the extracted objects and creates a perfectly tuned DEF table. Unlike the AI systems, the hybrid system is more debuggable and trainable. The hybrid system trains itself every day for each document type.
- No need to change the existing system
- More debuggable
- Easy to train
- The classifiers editable by experts
- The DEF tables are
- suspendable,
- updatable,
- removable,
- addable
- transportable (between the systems)
Interested in what CaptureFast can do for you? Just fill out the form and we’ll schedule a live demo of CaptureFast at a time that suits you.